Migrating Supernova to PlanetScale: Faster APIs, Better Insights
October 29, 2025
We moved our Postgres DB to PlanetScale Metal to cut latency and gain real query visibility—our app is noticeably faster.

What is Supernova?
At Supernova, we want to build an AI tutor for every learner—starting with spoken English. Learners practice by speaking with an AI that gives instant corrections and feedback in their mother tongue, available in eight Indian languages, with fully localized lessons for easy understanding. With 1.2 million monthly active users, we’re among the top 10 education apps in India.
Migrating to PlanetScale
About a month ago we migrated our production Postgres to PlanetScale Metal. Below is the short version of why, how, and what changed—numbers included.
Why we wanted to move
Keep app and DB in the same region (cut latency). Our main application runs on Vercel in AWS Mumbai, while our database was on DigitalOcean Bangalore. That cross-region hop added avoidable latency and jitter. Moving the database closer to the app was priority #1.
We needed real query insights. On DigitalOcean, it was hard to see which queries were slow or what changed during analytics-heavy periods. We had
pg_stat_statementsenabled, but making it actionable (dashboards, regressions, drilldowns) wasn’t straightforward or easily accessible. We wanted a lot more visibility.Considering AWS, chose PlanetScale Metal for performance. We were evaluating AWS RDS, but when PlanetScale Postgres Metal became available, it was a no brainer. From prior experience running Postgres on NVMe (vs. EBS), we knew the latency and IOPS gains are real, and Metal brings that profile with a managed experience.
How we migrated
Trim the payload. Before replication, we backed up and deleted a few very large log tables so the DB was smaller and faster to sync. (~1.1 TB → ~600 GB)
Set up logical replication. We used PlanetScale’s open-source Postgres logical replication scripts to create a subscriber and continuously mirror all tables from the old database.
Prepare deployments. We staged deployments (most traffic via Vercel, some via Cloudflare) preconfigured with the PlanetScale connection URL.
Disable the legacy write path. Just before cutover, we removed write permission on the role — eliminating any chance of straggler writes to the old DB.
Cut over. Once replication caught up, we promoted the prepared deployments so new writes flowed to PlanetScale.
Verify and watch. We monitored app metrics and PlanetScale Insights to confirm healthy latency and query behavior post-switch.
Results
Faster APIs immediately. All APIs got a faster, and p99 was a lot more consistent. These are are numbers for a read-heavy endpoint that fires lots of queries:
p50: 334 ms → 92 ms (–72%)
p75: 450 ms → 126 ms (–72%)
p90: 500 ms → 170 ms (–66%)
Here are the overall API latencies:
This chart show the overall API latency of one full day on PlanetScale compared with a week earlier:
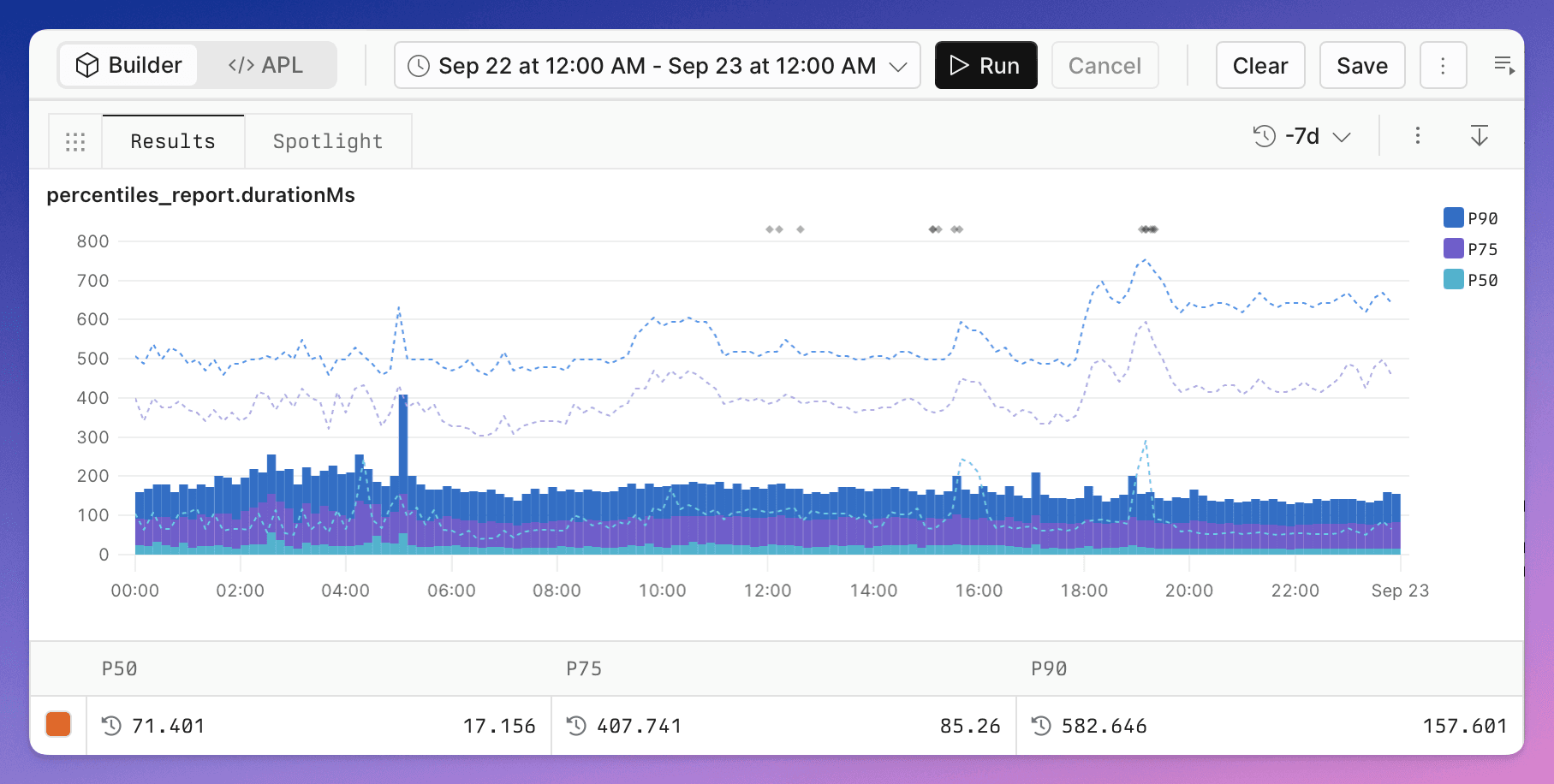
This chart shows the API response before and after migration:
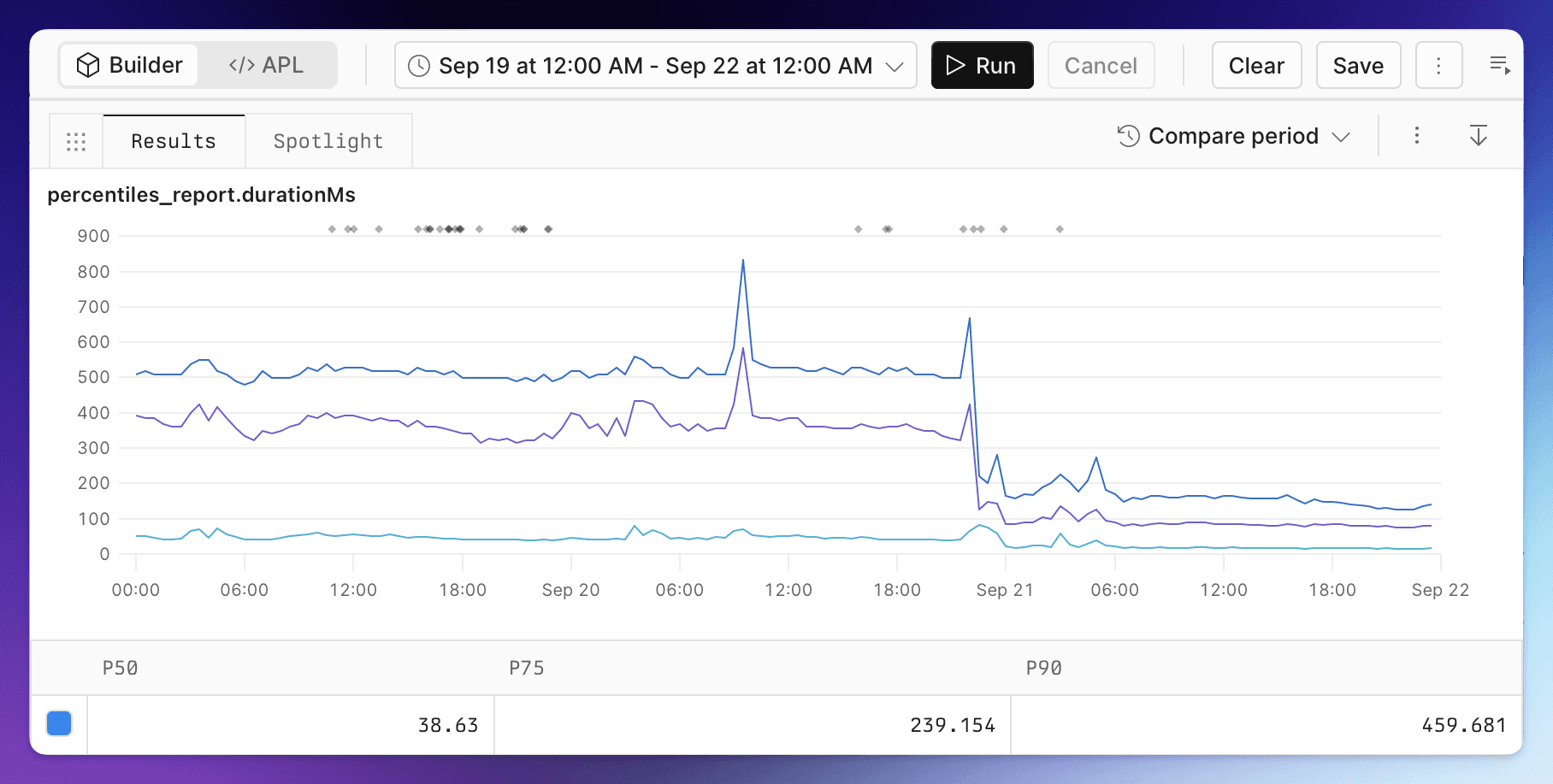
It’s remarkable, p90 is lesser than p75 on the earlier provider.
Query performance headroom. On the primary database, our p99 single-query time ≤ 5 ms, giving us plenty of room before needing to re-optimize hot paths.
Lower load on smaller hardware. We moved from a 16-core DigitalOcean box (CPU ~40% most of the time) to an 8-core PlanetScale Metal instance where CPU rarely exceeds 20%—typically only during big cron runs. Net: faster on fewer cores with lots more breathing room.
Insights → quick wins. The Insights dashboard immediately surfaced missing indexes and slow queries. We added targeted indexes, corrected offenders, and saw instant gains.
Cost. PlanetScale cost is about 20% higher, but it isn’t a true comparison. On DigitalOcean we had two instances, a primary and a read replica. PlanetScale gives us three equally sized machines. And as mentioned above, we are over provisioned on the primary so there is scope to reduce to a smaller instance size and save cost.
Post migration surprise & fixes
After the move, we noticed high egress bandwidth usage (DigitalOcean’s generous free bandwidth tier had masked this). PlanetScale bills bandwidth roughly at AWS rates (0.1 USD per GB egress), so we reached out—and the team was incredibly helpful and hands-on in helping us figure out the issue. They even waived off bandwidth charges while we investigated.
PlanetScale also shipped an Insights enhancement showing per-query bandwidth usage. With that visibility, a bit more judicious query design, and extra caching, we cut bandwidth significantly in 2–3 days.
Throughout the process, the PlanetScale team was responsive and engaged. Working with them has been an absolute pleasure.
Overall, we’re very happy with the move—it’s made our app much faster, and we’re confident PlanetScale can support our growing needs. If you’re considering a similar migration or want more details, reach out—we’re happy to share our approach and lessons learned.
PS: We are hiring! If you are excited to work on the intersection of cutting edge AI and education we are hiring for AI Engineers and React Native Engineers. Check out the job listing on how to apply!